Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language. However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined. To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs. Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs. This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance. To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs’ awareness of corruptions to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
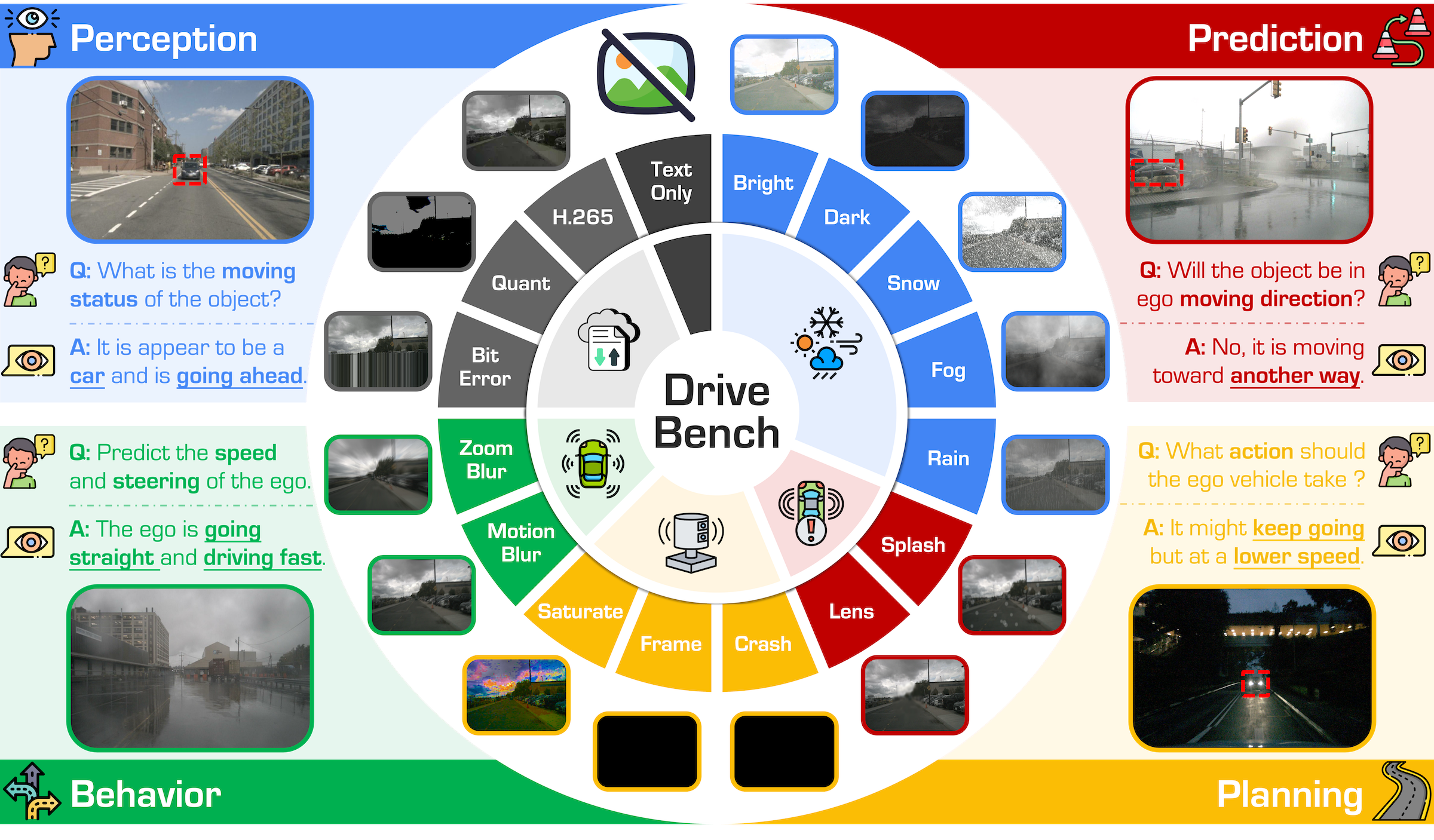
Overview of key features and configurations in DriveBench. Our benchmark evaluates the reliability and visual grounding of VLMs in autonomous driving across four mainstream driving tasks - perception, prediction, planning, and explanation - under a diverse spectrum of 17 settings (clean, corrupted, and text-only inputs). It includes 19,200 frames and 20,498 QA pairs spanning three question types: multiple-choice, open-ended, and visual grounding. By addressing diverse tasks and conditions, we aim to reveal VLM limitations and promote reliable, interpretable autonomous driving.
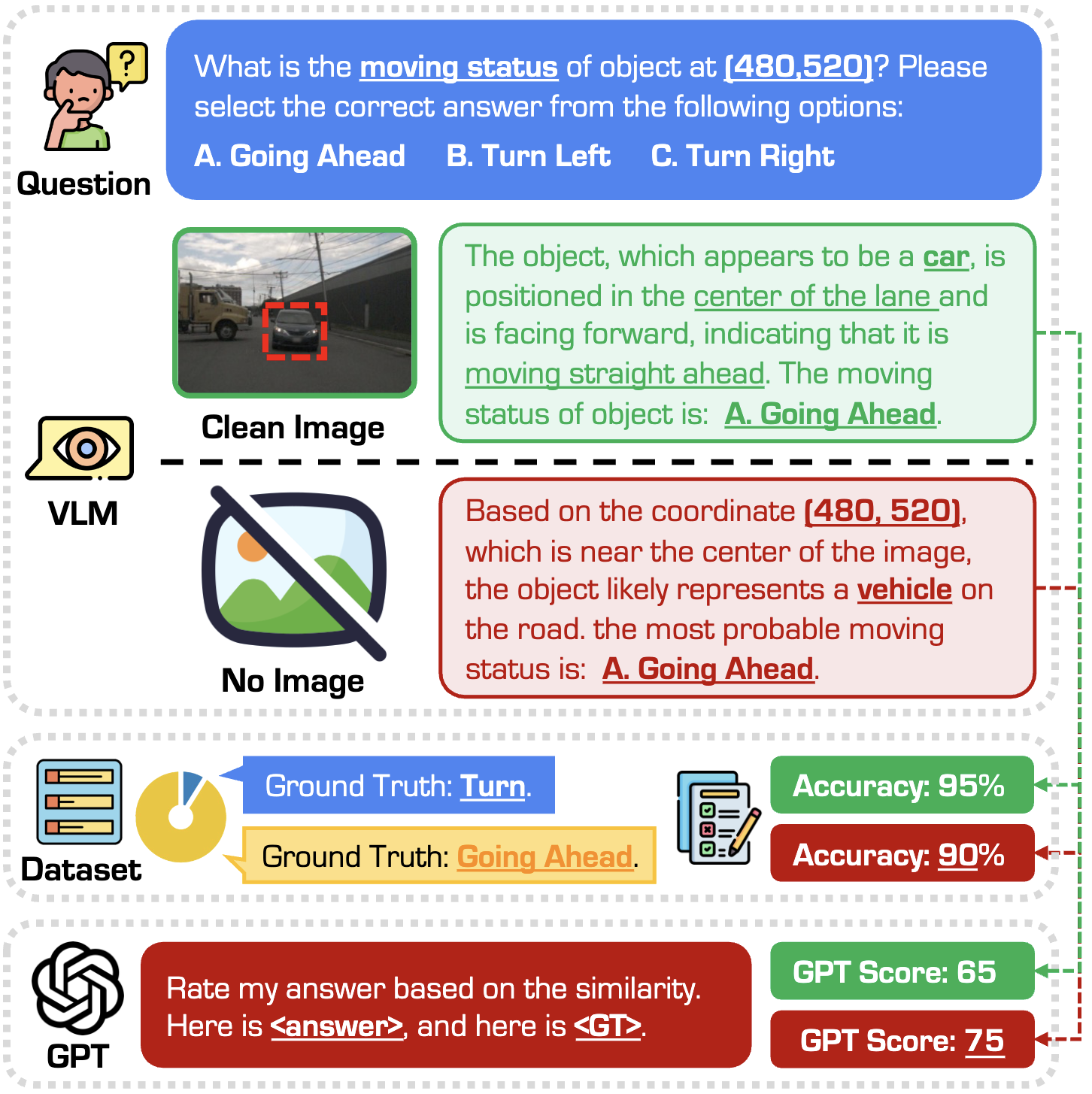
We investigate this question through the lenses of reliability, data quality, and evaluation metrics. Our findings reveal that current VLMs often fabricate convincing answers to driving-related questions, even in the absence of visual information. These fabricated responses can bypass existing evaluation metrics, including GPT scores, due to issues such as dataset imbalance, insufficient contextual data, and flawed evaluation protocols. These observations challenge the widely held assumption that VLMs inherently provide more reliable, visually grounded, and interpretable responses than task-specific models in driving scenarios.




| Benchmark | Frames | QA | Logic | Evaluation Metrics | |||||
|---|---|---|---|---|---|---|---|---|---|
| (Test) | (Test) | ||||||||
| BDD-X | ✔ | ✘ | ✘ | ✘ | ✘ | - | - | None | Language |
| BDD-OIA | ✔ | ✘ | ✔ | ✘ | ✘ | - | - | None | F1 Score |
| nuScenes-QA | ✔ | ✘ | ✘ | ✘ | ✘ | 36,114 | 83,337 | None | Acc |
| Talk2Car | ✔ | ✘ | ✘ | ✔ | ✘ | ~1.8k | 2,447 | None | - |
| nuPrompt | ✔ | ✘ | ✘ | ✘ | ✘ | ~36k | ~6k | None | AMOTA |
| DRAMA | ✔ | ✘ | ✘ | ✔ | ✘ | - | ~14k | Chain | Language |
| Rank2Tel | ✔ | ✘ | ✘ | ✔ | ✘ | - | - | Chain | Acc, Language |
| DirveMLLM | ✔ | ✘ | ✘ | ✘ | ✘ | 880 | - | None | Acc |
| DriveVLM | ✔ | ✘ | ✔ | ✔ | ✘ | - | - | None | GPTctx |
| DriveLM | ✔ | ✔ | ✔ | ✔ | ✘ | 4,794 | 15,480 | Graph | Language, GPT |
| DriveBench (Ours) | ✔ | ✔ | ✔ | ✔ | ✔ | 19,200 | 20,498 | Graph | Acc, Language, GPT, GPTctx |
We analyze existing “Driving with Language” benchmarks and identify their issues, particularly dataset imbalance inherited from sources like nuScenes, BDD, and Waymo Open. Our benchmark addresses these issues by curating a balanced dataset with diverse driving tasks, corruption types, and text-only inputs, enabling systematic evaluation of VLMs under real-world autonomous driving conditions. This ensuress a reliable testbed for assessing VLMs in safety-critical scenarios.
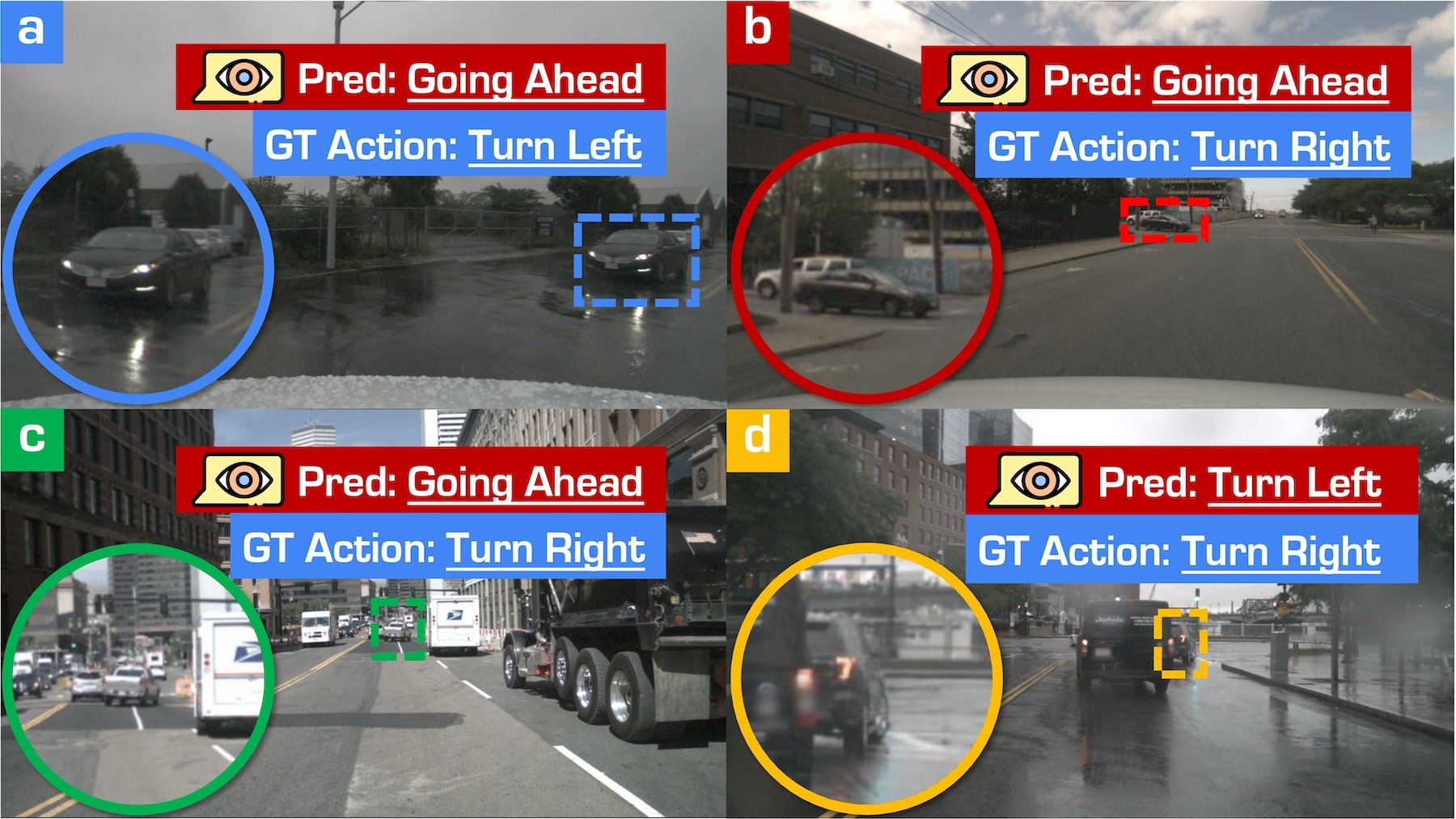
(a): The black sedan is turning left, indicated by the turn lights. (b): The black sedan is turning right. GPT4-o predicts Going Ahead for these two cases.
(c) and (d) are both Turning Right, but GPT4-o fails to locate the objects based on center pixel positions due to the existence of overlapping or occlusion.
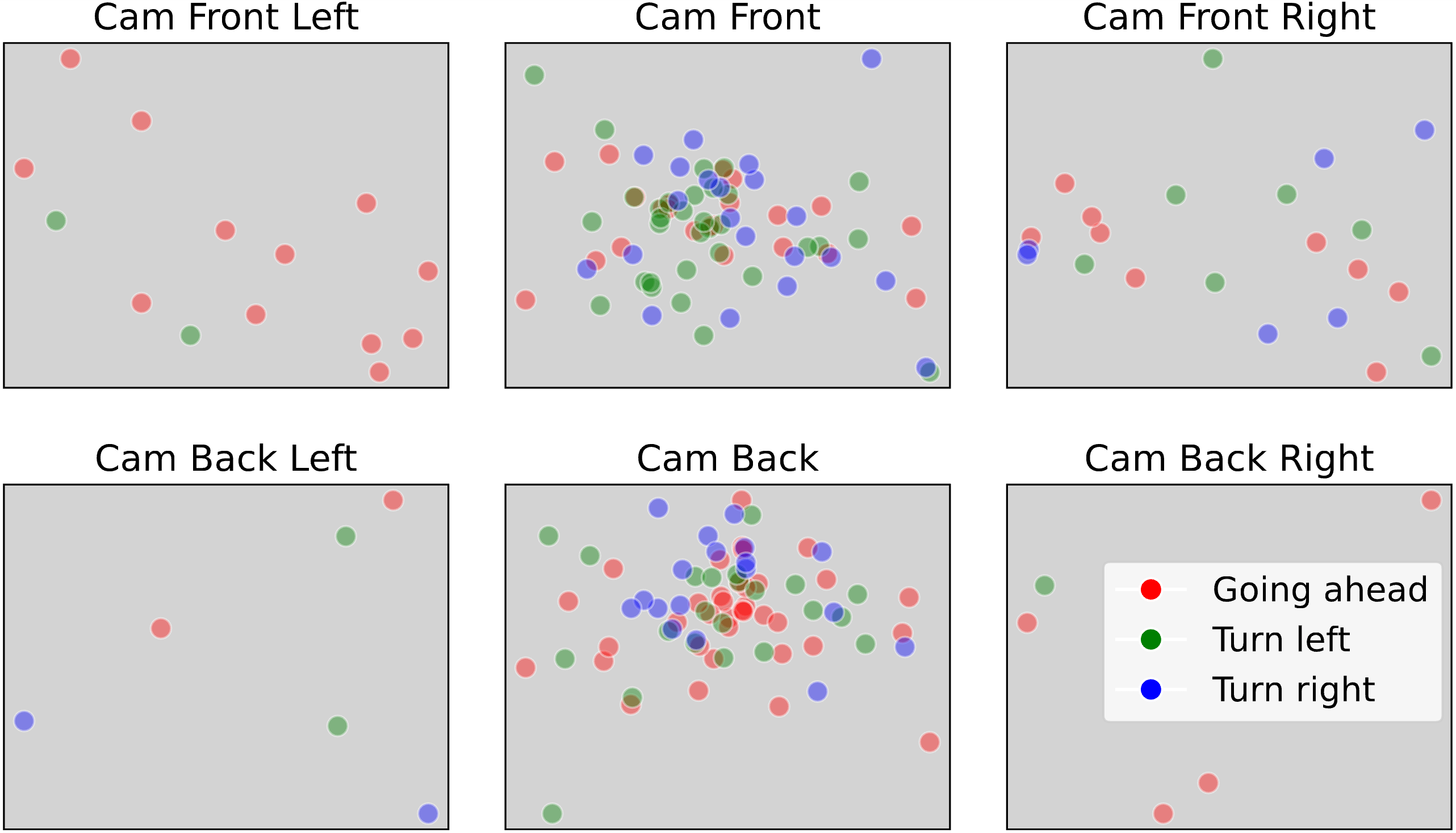
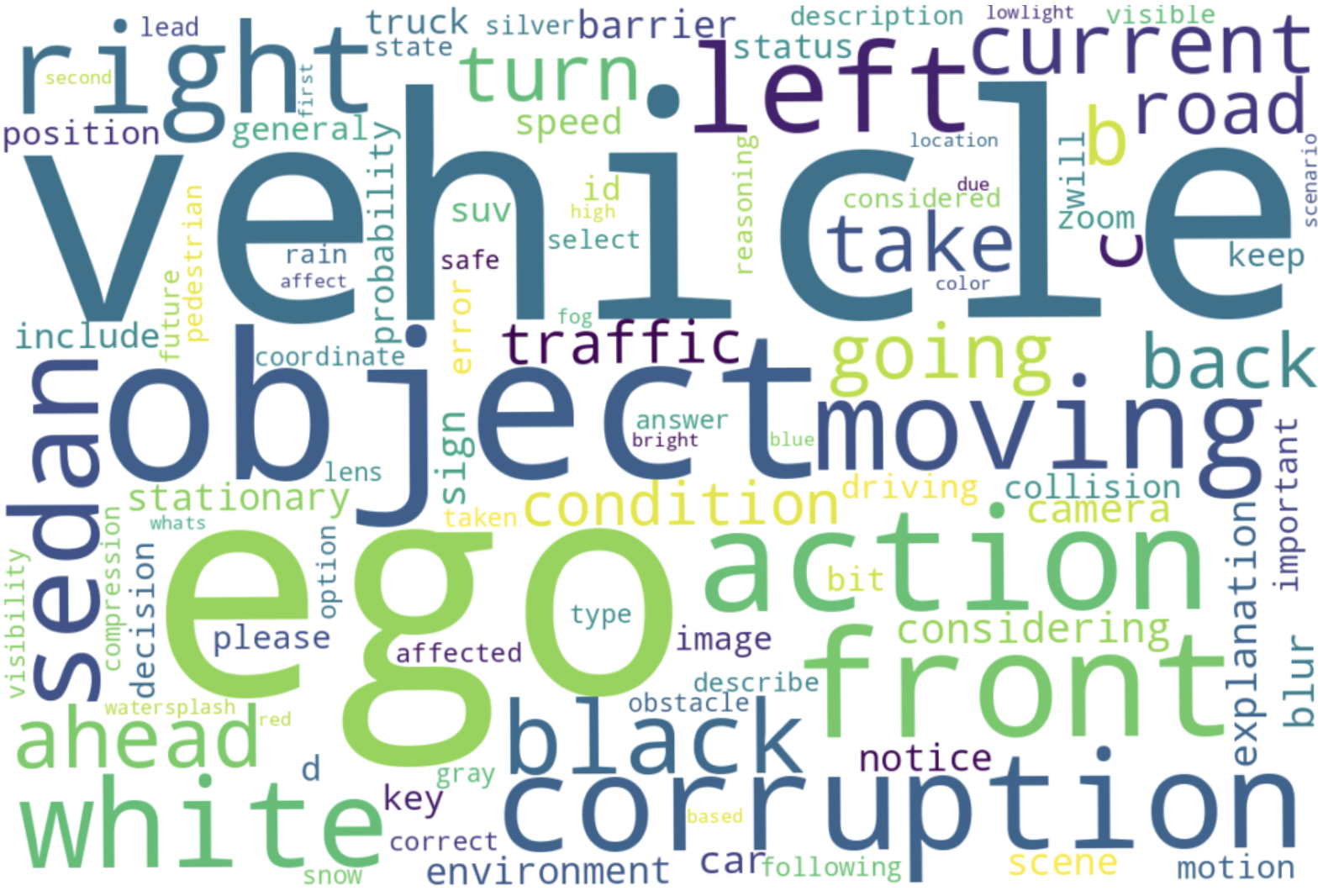
We study the spatial distribution of predictions generated by Qwen2-VL (7B), under the text-only prompts. We find that the model can potentially “guess” the MCQ answers without visual information by leveraging plain text cues, e.g., camera and coordinate positions mentioned in the questions, resulting in the hallucination issue.
| Model | Size | Type | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Human | - | - | 47.67 | 38.32 | - | - | - | - | - | - | - | 69.51 | 54.09 | - |
| GPT-4o | - | Commercial | 35.37 | 35.25 | 36.48 | 51.30 | 49.94 | 49.05 | 75.75 | 75.36 | 73.21 | 45.40 | 44.33 | 50.03 |
| LLaVA-1.5 | 7B | Open | 23.22 | 22.95 | 22.31 | 22.02 | 17.54 | 14.64 | 29.15 | 31.51 | 32.45 | 13.60 | 13.62 | 14.91 |
| LLaVA-1.5 | 13B | Open | 23.35 | 23.37 | 22.37 | 36.98 | 37.78 | 23.98 | 34.26 | 34.99 | 38.85 | 32.99 | 32.43 | 32.79 |
| LLaVA-NeXT | 7B | Open | 24.15 | 19.62 | 13.86 | 35.07 | 35.89 | 28.36 | 45.27 | 44.36 | 27.58 | 48.16 | 39.44 | 11.92 |
| InternVL2 | 8B | Open | 32.36 | 32.68 | 33.60 | 45.52 | 37.93 | 48.89 | 53.27 | 55.25 | 34.56 | 54.58 | 40.78 | 20.14 |
| Phi-3 | 4.2B | Open | 22.88 | 23.93 | 28.26 | 40.11 | 37.27 | 22.61 | 60.03 | 61.31 | 46.88 | 45.20 | 44.57 | 28.22 |
| Phi-3.5 | 4.2B | Open | 27.52 | 27.51 | 28.26 | 45.13 | 38.21 | 4.92 | 31.91 | 28.36 | 46.30 | 37.89 | 49.13 | 39.16 |
| Oryx | 7B | Open | 17.02 | 15.97 | 18.47 | 48.13 | 46.63 | 12.77 | 53.57 | 55.76 | 48.26 | 33.92 | 33.81 | 23.94 |
| Qwen2-VL | 7B | Open | 28.99 | 27.85 | 35.16 | 37.89 | 39.55 | 37.77 | 57.04 | 54.78 | 41.66 | 49.07 | 47.68 | 54.48 |
| Qwen2-VL | 72B | Open | 30.13 | 26.92 | 17.70 | 49.35 | 43.49 | 5.57 | 61.30 | 63.07 | 53.35 | 51.26 | 49.78 | 39.46 |
| DriveLM | 7B | Specialist | 16.85 | 16.00 | 8.75 | 44.33 | 39.71 | 4.70 | 68.71 | 67.60 | 65.24 | 42.78 | 40.37 | 27.83 |
| Dolphins | 7B | Specialist | 9.59 | 10.84 | 11.01 | 32.66 | 29.88 | 39.98 | 52.91 | 53.77 | 60.98 | 8.81 | 8.25 | 11.92 |
| Model | Size | Type | Weather |
External |
Sensor |
Motion |
Transmission |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MCQ | VQA | CAP | MCQ | VQA | CAP | MCQ | VQA | CAP | MCQ | VQA | CAP | MCQ | VQA | CAP | |||
| GPT-4o | - | Commercial | 57.20 | 57.28 | 54.90 | 29.25 | 56.60 | 61.98 | 44.25 | 54.95 | 56.53 | 34.25 | 59.20 | 56.25 | 36.83 | 53.95 | 57.57 |
| LLaVA-1.5 | 7B | Open | 69.70 | 35.49 | 35.91 | 26.50 | 29.17 | 34.95 | 18.83 | 30.64 | 33.15 | 71.25 | 33.43 | 35.18 | 10.17 | 27.28 | 34.38 |
| LLaVA-1.5 | 13B | Open | 61.60 | 39.76 | 37.76 | 15.50 | 34.55 | 37.83 | 24.08 | 35.48 | 36.08 | 79.75 | 36.46 | 36.42 | 15.50 | 32.53 | 34.33 |
| LLaVA-NeXT | 7B | Open | 69.70 | 36.96 | 48.52 | 48.50 | 30.32 | 57.18 | 21.83 | 30.40 | 44.37 | 66.00 | 34.20 | 50.44 | 11.83 | 29.43 | 53.50 |
| InternVL2 | 8B | Open | 59.90 | 48.72 | 48.60 | 50.75 | 47.74 | 57.82 | 29.92 | 45.06 | 51.14 | 68.25 | 49.51 | 49.67 | 30.00 | 43.42 | 54.24 |
| Phi-3 | 4.2B | Open | 40.00 | 40.59 | 45.61 | 25.00 | 31.44 | 45.99 | 16.83 | 35.58 | 43.71 | 31.25 | 42.92 | 48.43 | 27.67 | 33.04 | 41.35 |
| Phi-3.5 | 4.2B | Open | 60.60 | 41.82 | 45.97 | 21.25 | 36.89 | 30.95 | 25.58 | 34.66 | 39.30 | 33.00 | 46.03 | 49.33 | 39.67 | 33.47 | 39.67 |
| Oryx | 7B | Open | 53.20 | 40.43 | 48.95 | 45.00 | 40.68 | 56.06 | 50.50 | 36.71 | 48.55 | 72.50 | 40.01 | 48.33 | 39.67 | 36.98 | 49.87 |
| Qwen2-VL | 7B | Open | 76.70 | 49.33 | 45.12 | 37.50 | 47.62 | 51.24 | 22.83 | 39.45 | 47.23 | 57.00 | 47.40 | 47.74 | 35.83 | 42.31 | 48.60 |
| Qwen2-VL | 72B | Open | 59.80 | 51.05 | 48.55 | 45.50 | 50.57 | 57.25 | 52.25 | 45.89 | 48.59 | 58.25 | 50.85 | 47.88 | 44.83 | 46.23 | 50.50 |
| DriveLM | 7B | Specialist | 21.20 | 42.86 | 20.04 | 21.25 | 37.49 | 21.92 | 9.00 | 36.68 | 15.56 | 22.25 | 42.05 | 17.07 | 17.50 | 39.56 | 10.37 |
| Dolphins | 7B | Specialist | 54.30 | 30.21 | 31.08 | 3.00 | 30.42 | 29.38 | 9.42 | 26.83 | 26.30 | 9.25 | 29.82 | 28.05 | 21.50 | 28.86 | 27.65 |
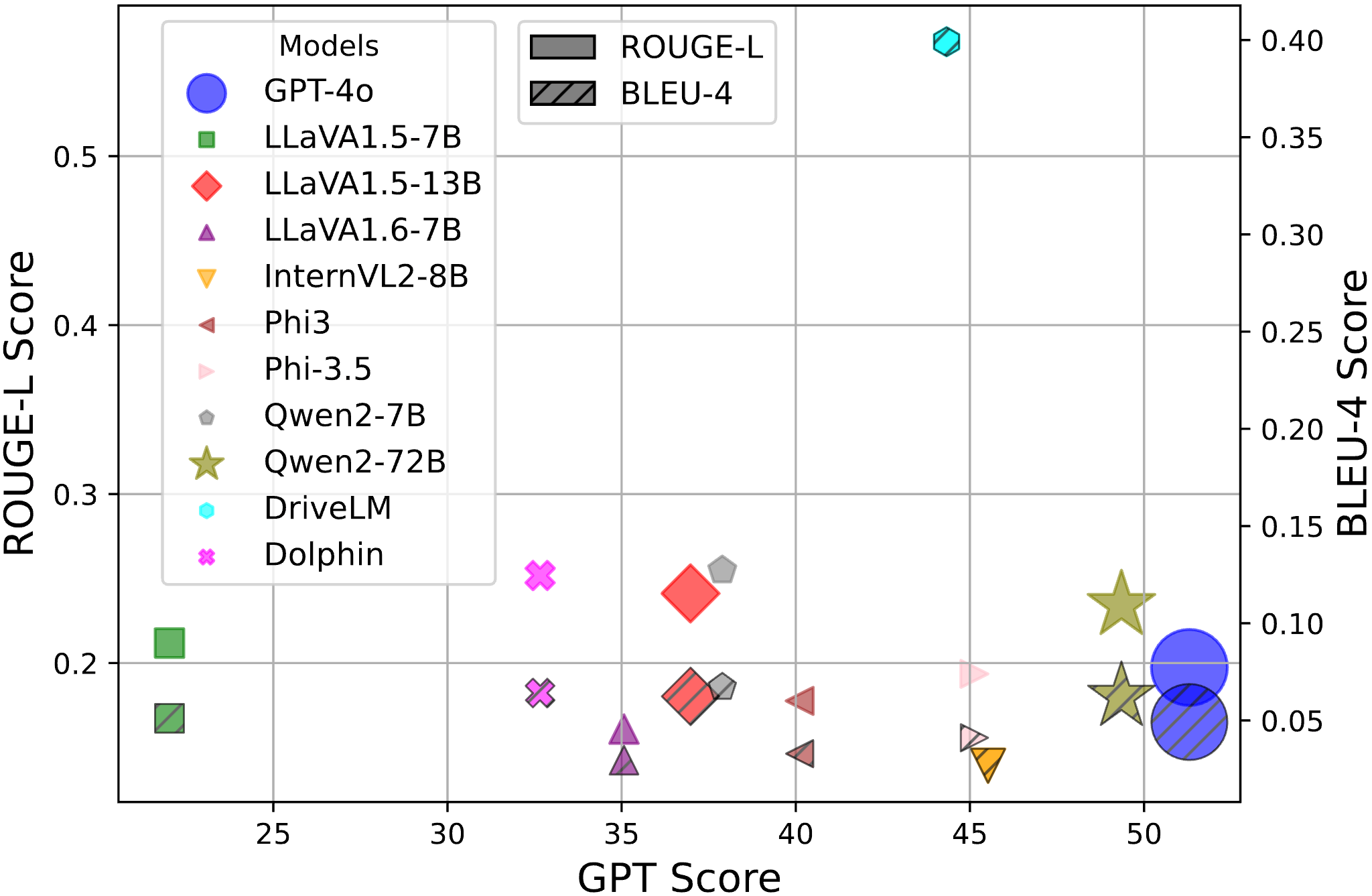
Evaluation results when using different metrics. The language metrics, such as ROUGE-L and BLEU-4, exhibit high consistency; while the GPT Score metric demonstrates a noticeable gap compared to existing language metrics. We also observe that fine-tuned process benefits DriveLM significantly in regulating its response format, thus leading to misleading high performance under language metrics.
We notice that the majority actions of vehicle behaviors are “Going Ahead”, while only a small proportion of actions are “Turn Left” or “Turn Right”.
This leads to the data distribution imbalance issue in evaluating different vision-language models.
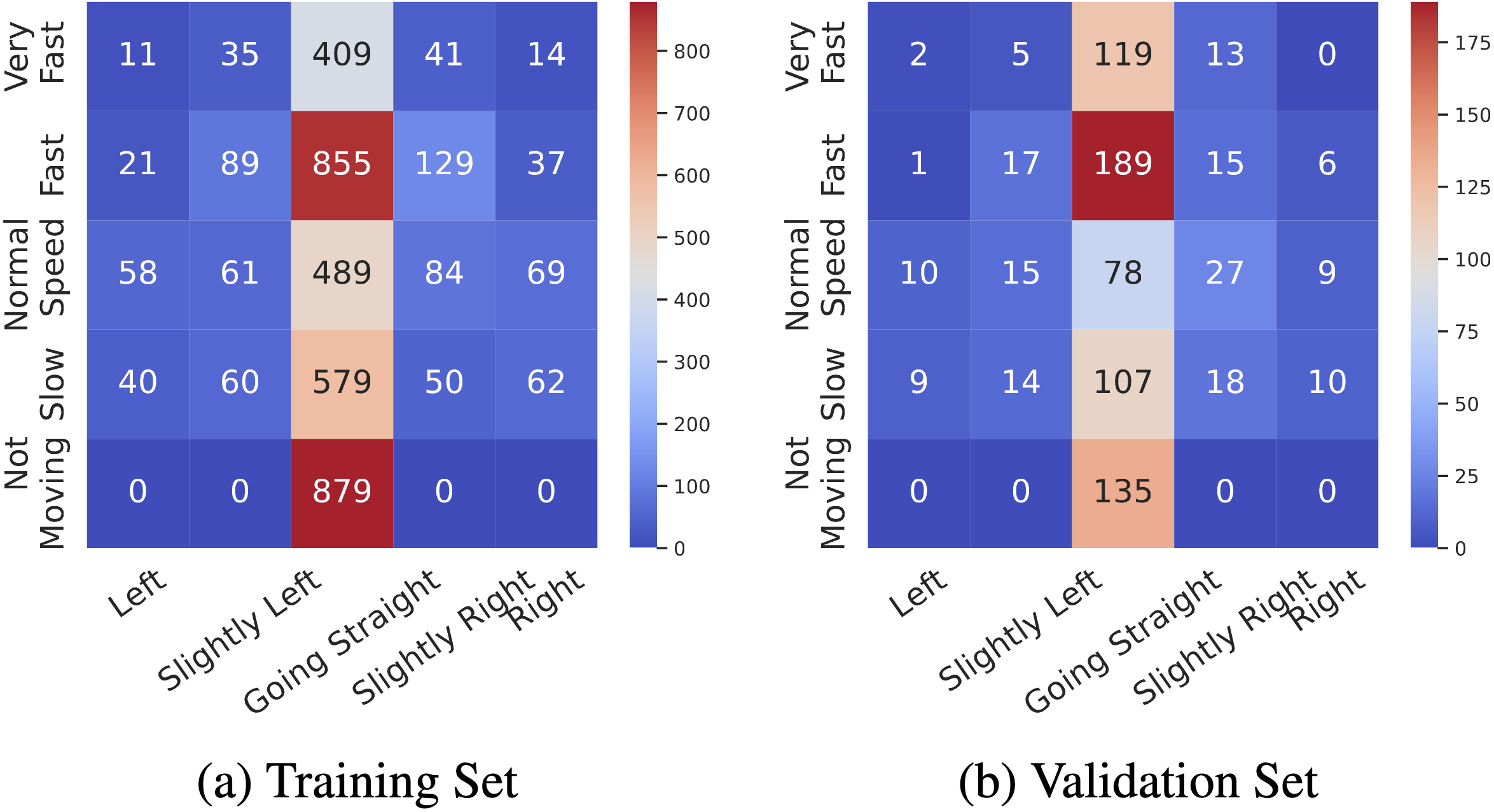

Figure. Examples of GPT-4o responses to four tasks and the corresponding evaluation results under the Dark condition. We observe that GPT-4o is aware of the low-light environment and can identify the bus and pedestrian from the image, showing certain degrees of resilience.

Figure. Examples of GPT-4o response to four tasks and the corresponding evaluation results under the Motion Blur condition. We observe that GPT-4o are influenced by this type of corruption and tend to predict "driving fast" based on it. The example shows the potential of visual corruption to influence high-level driving decisions.
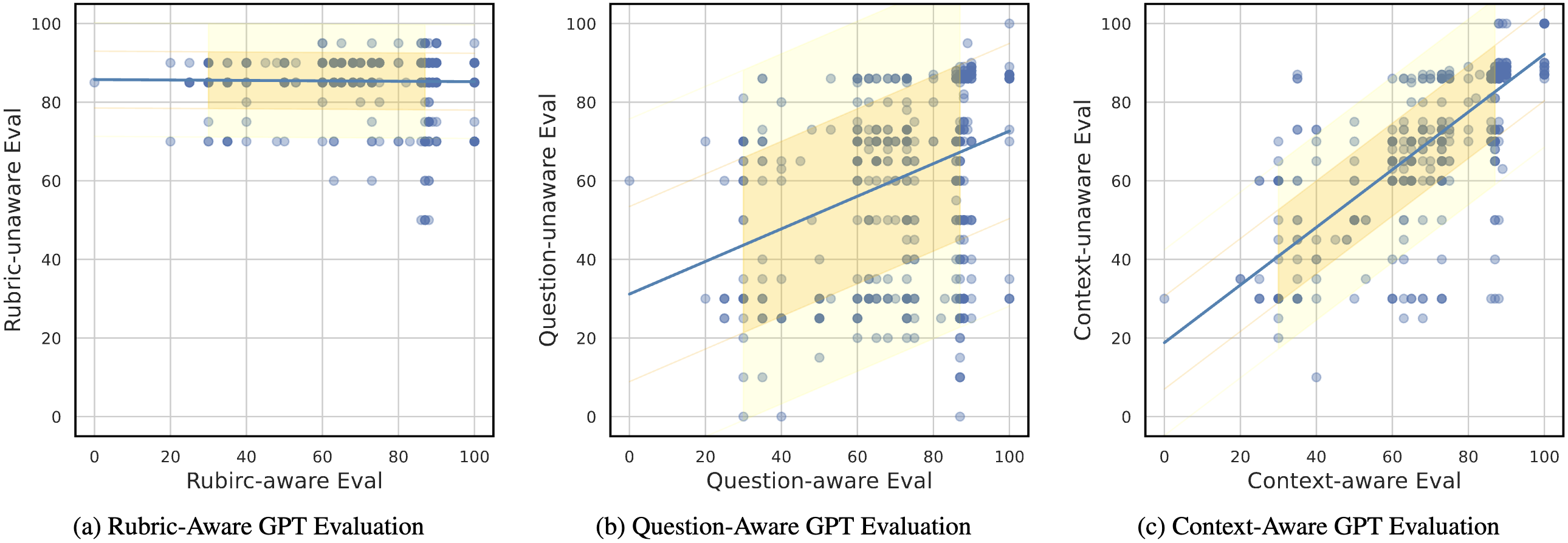
Figure. Comparisons among Different Evaluation Types (rubric, question-aware, and context-aware). The GPT scores vary depending on the rubric, question, and physical driving context. With more information added, the results become more distinguishable.
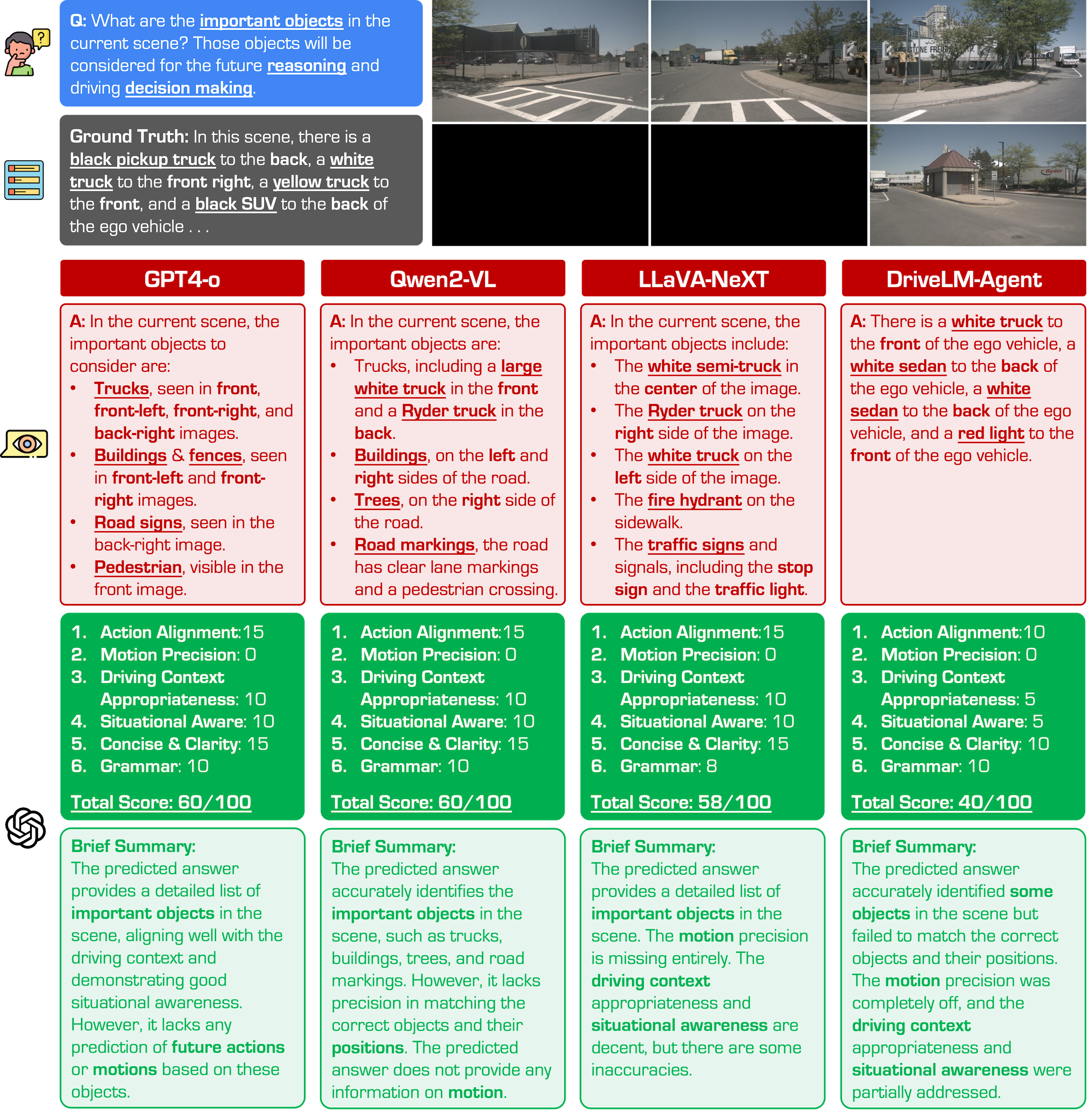
Figure. Examples of different VLM responses under the Frame Lost condition. We observe that GPT-4o responses with visible objects while LLaVA-NeXT and DriveLM tend to hallucinate objects that cannot be seen from the provided images.
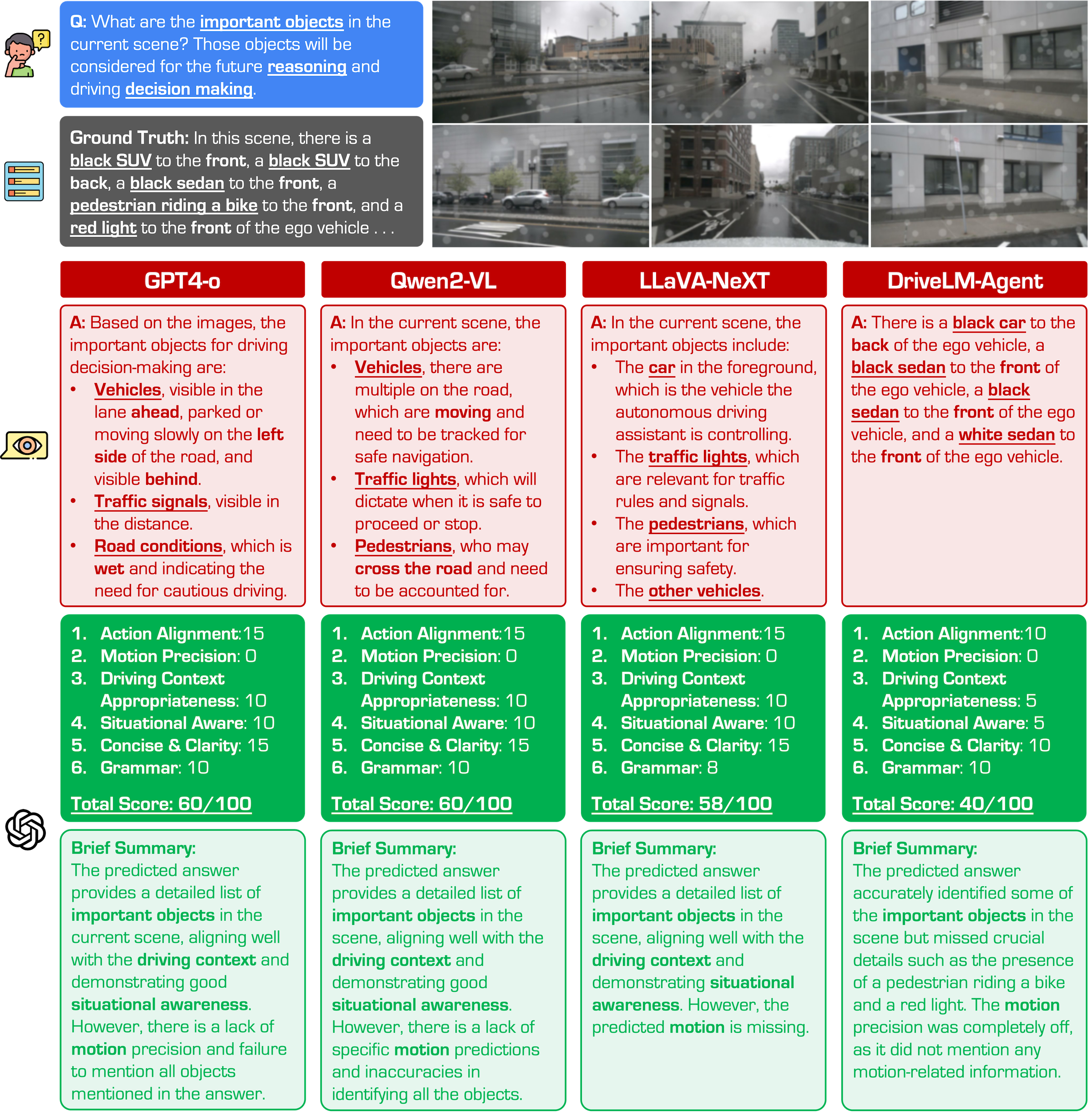
Figure. Examples of different VLM responses under the Water Splash condition. We observe that, under severe visual corruptions, VLMs respond with ambiguous and general answers based on their learned knowledge, without referring to the visual information. Most responses include traffic signals and pedestrians, even though they are not visible in the provided images.
@InProceedings{xie2025drivebench,
author = {Xie, Shaoyuan and Kong, Lingdong and Dong, Yuhao and Sima, Chonghao and Zhang, Wenwei and Chen, Qi Alfred and Liu, Ziwei and Pan, Liang},
title = {Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data and Metric Perspectives},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {6585-6597}
}